Building a news digest bot with LLMs & 3rd party APIs

TL;DR
I created a custom news digest bot to provide a daily summary of local news, weather, and microlearning content after facing limitations with Axios Local. I ran into the following challenges along the way:
- Problem: Duplicate articles from multiple local RSS feeds
Solution: Used the Levenshtein distance algorithm to filter and prioritize articles based on title similarity. - Problem: Hallucinations in LLM-based article summarization
Solution: Implemented Prompt Chaining and using a more reliable cloud based LLM (Llama-3.3-70B-Versatile) and a fact-checking process to ensure accuracy. - Problem: Large token counts causing 429 errors
Solution: Optimized summarization by feeding article text directly to the LLM using Postlight Parser to extract key details, for everything else it's prompt chaining with some sophisticated prompts.
Despite occasional hallucinations, the bot is working well, providing a personalized news summary for me and a few others.
For those of us without a cable subscription, the decline in local news has been a constant challenge. A few years ago, I came across Axios Local in Nashville, which delivers a short daily news digest featuring local sources. Here’s a snippet from one of them:
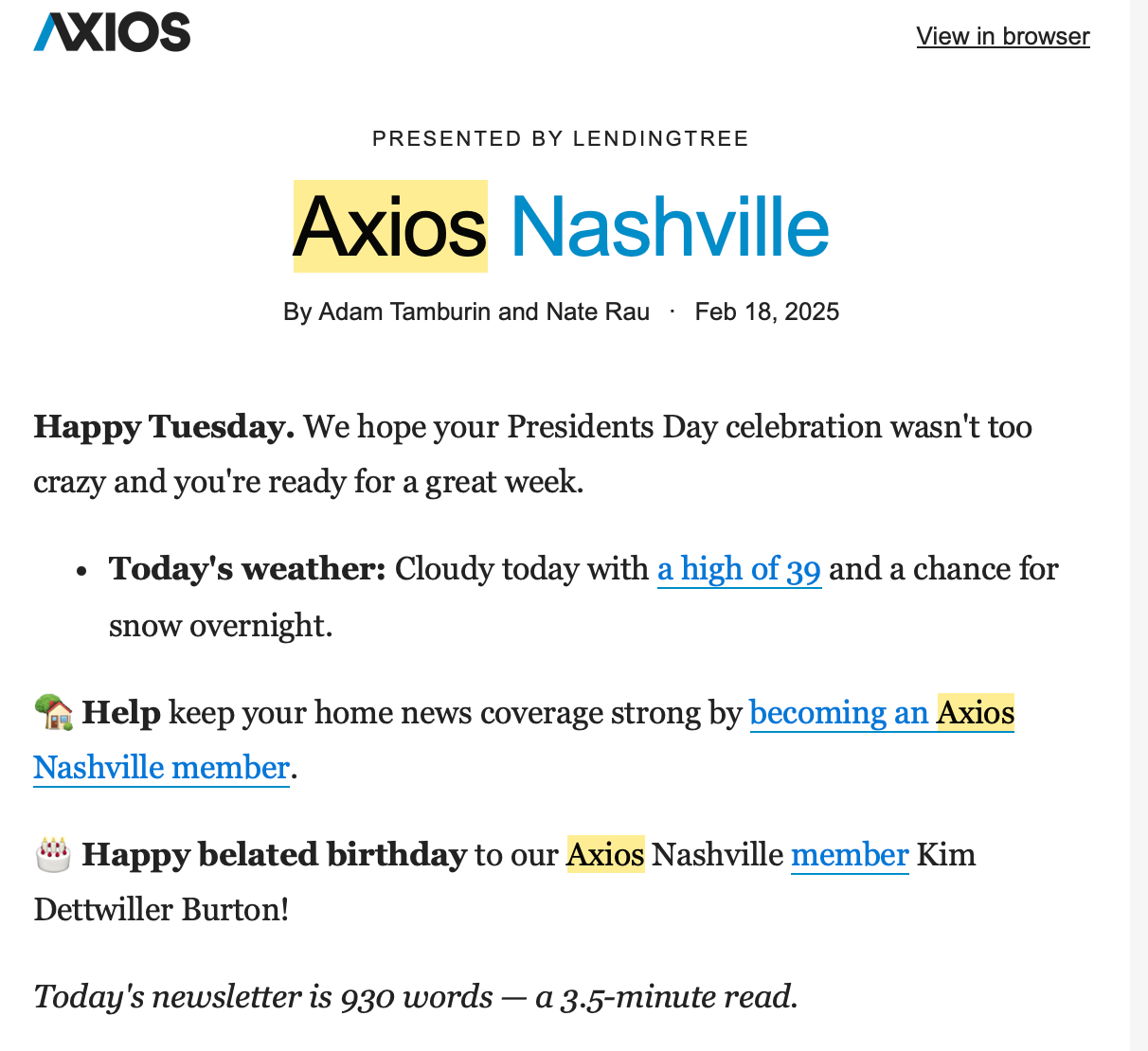
This format was a nice way to start the day. However, I started noticing a few issues that pushed me toward building my own solution. For one, the digest only includes today’s weather—I’d much prefer a weekly forecast. More importantly, though, the inclusion of political ads disguised as news articles was a dealbreaker.
That got me thinking: as a developer, I could build something that better suited my needs while adding some extra features.
Goals
The goal was simple: build a similar news digest bot that includes the following:
- A fun greeting that incorporates holidays
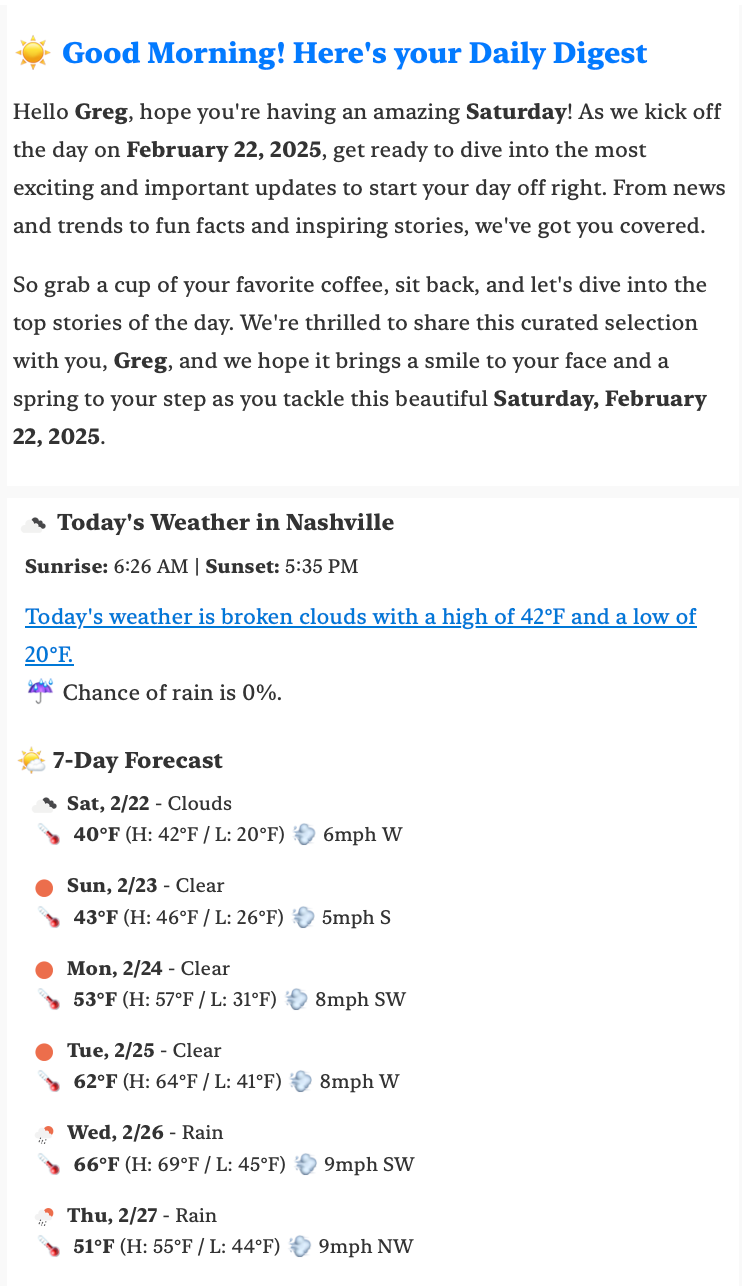
- The weather for the day and a weekly forecast
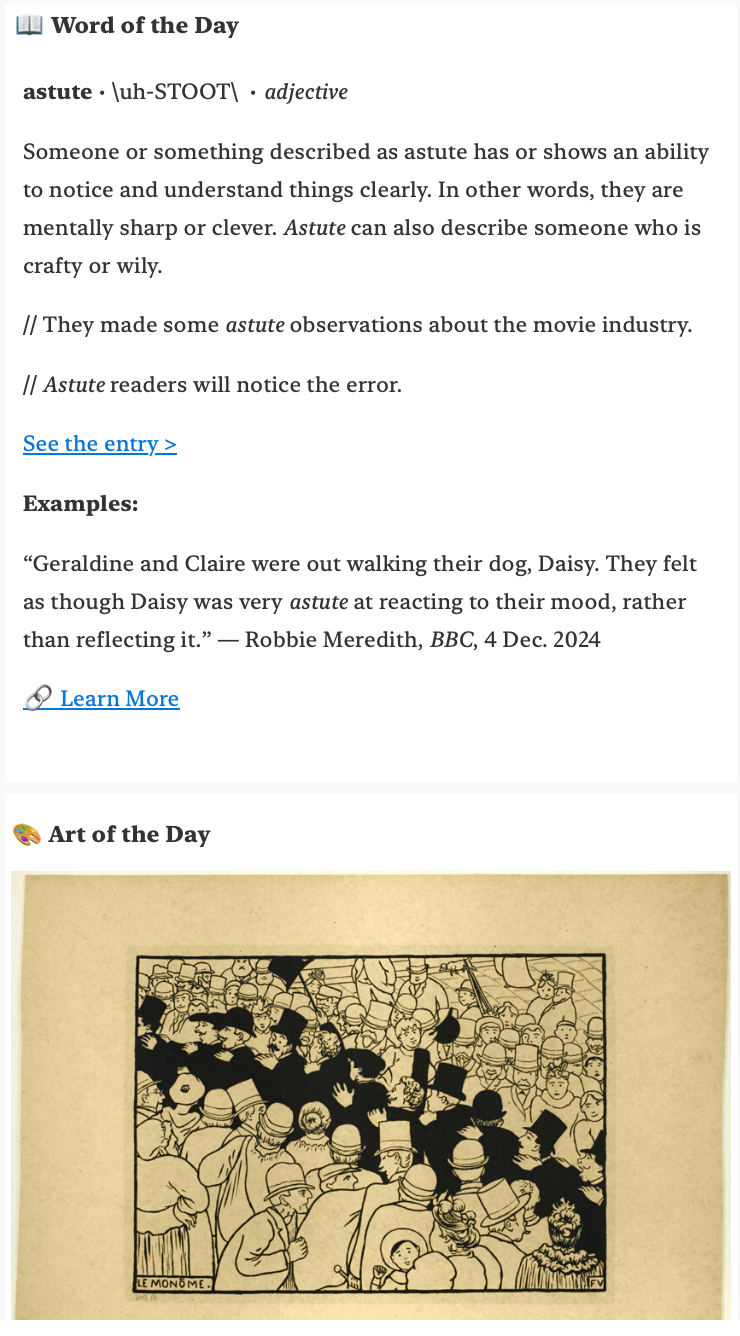
- Some microlearning to start the day off right
- Local news sources and some specific news alert feeds
For text generation, I experimented with a few different approaches. My goal was to find a cheap—or free—solution that could generate accurate article summaries and custom content while keeping things fresh.
Tech Stack
This project is open source and available on GitHub!
- bcd-good-morning: The main email bot
- bcd-article-parser: A Node Express API that pulls detailed information from article URLs
Like most of my projects, I built this using the language I’m most familiar with: C#. The solution also relies on third-party services for weather, news, and text generation:
- Weather - https://openweathermap.org/
- Holidays - https://calendarific.com/
- Microlearning - Wikipedia, Art Institute of Chicago, Merriam-Webster's Word of the Day
- Article Parsing – A Node Express app running Postlight Parser
Both services run on my home Kubernetes cluster and use a Kubernetes cron job execute.
The Challenges
As expected, a project such as this ran into a number of challenges. Let's walk through them:
Problem: For news aggregation, I pulled from multiple RSS feeds, including local news sites and Google News RSS. The issue? Many local sources reported on the same stories, leading to duplicate or near-duplicate articles clogging up the email. I needed a way to filter out redundant content while still ensuring coverage from multiple different local sources.
Solution: Since RSS feeds include article titles, I could use an algorithm to determine similarity between articles and keep only the ones I wanted from my highest-weighted sources. There are several ways to do this, but I chose the Levenshtein distance algorithm, which calculates the differences between string sequences. In simple terms, it measures how similar two pieces of text are. This algorithm is nicely packaged for C# in the FuzzySharp Nuget package.
Next Problem: LLMs hallucinations!

This challenge took some trial and error to solve. I’m a big proponent of self-hosting, and I run a small Ollama setup on a Mac Mini M4. While a lightweight model like gemma2 is great, and can even use tools to pull content from the web, it struggled significantly with hallucinations when summarizing articles. For example:
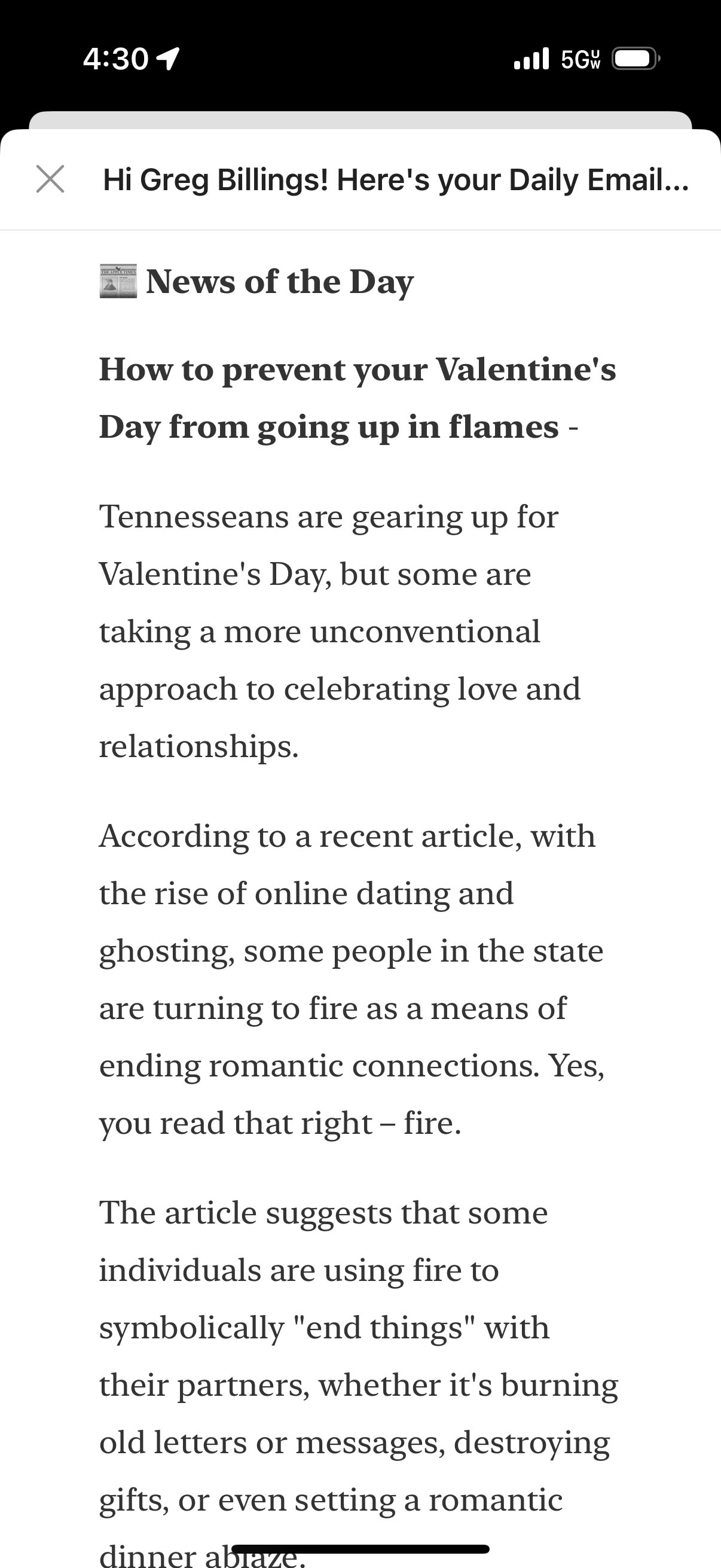
The actual article made no mention of couples setting dinners on fire. It was simply about candle safety. Needless to say, having a news digest bot hallucinating like this was not ideal. Especially one that is so sure of itself, it even doubles down.
Solution: Since I didn’t have the necessary compute power to run a more reliable model locally, I looked for larger models I could access via an API—for free. That’s when I discovered GroqCloud, which remains my go-to solution.
Even with a more powerful model (I’m using Llama-3.3-70B-Versatile), I still ran into issues with the finer details, like incorrect numbers and dates. To improve accuracy, I leveraged a concept called Prompt Chaining. This technique involves breaking down tasks into multiple prompts, sometimes even using different models in sequence, where the output of one prompt serves as input for the next.
Here’s an example of how I structured my prompts:
Your job is to pull out small, numbered facts from this article. Do not use opinions. Number each fact. The article is located at {article.Link}.
You are a fact checker for a news organization. Your job is to mark facts as true or false. If the fact is false, suggest a correction. Review the facts and compare them against the news article. The facts are: {article.OriginalSummary}. The article is located at {article.Link}. Use other sources as required to verify the facts. Mark the fact as undetermined if you cannot verify it.
You are an editor for a news organization. Review the facts provided and correct them with the provided suggestions. Remove facts that are marked as undetermined. Include the name of the sources with the facts. Your output should be the corrected facts in a numbered list. Do not include any headers or other information. The facts are: {article.OriginalSummary}.
You are a news digest bot. Your job is to create an extractive summary of an article in 1-2 paragraphs. Use the provided facts to drive the summary and guarantee correctness. Use near exact sentences from the article in your summary. Do not use opinion. Do not make up any information. The summary should only include information from the article. Do not use any third party sources. The summary should introduce the article to the reader. Avoid headers or the website URL. Structure the summary in a way that best fits the article. If relevant, include bullet points for information. Use HTML tags such as <p>, <ol>, <li> etc for better readability.
This approach worked really well—it generated summaries with the most relevant details while avoiding hallucinations.
However, there was one major drawback: token usage. The bot burned through a lot of tokens, hitting the 100K daily limit after processing just five articles, resulting in 429 errors (rate limiting).
Last Problem: Large token counts causing rate limiting.
Solution: Pay more money. Nope! Instead, I took two approaches:
- Directly feed in the article text. Instead of asking the model to visit the URL, I fed it the article text directly. This greatly reduced hallucinations, likely because it eliminated site content like ads and other links. Feeding in the exact article text allowed me to eliminate most of the prompt chains. I used the Postlight Parser (an NPM package) to extract the full article text for the LLM. With this approach, because the articles are fairly short, token counts stayed in the low hundreds. This mostly solved the rate limiting.
- Handle restricted articles separately. For articles blocked by CAPTCHA prevention, I still allowed the LLM to visit the site but ran it through two structured prompts to reduce my token usage:
You are a news bot.
Your job is to pull out important key facts from an article.
Do not use opinions.
The facts should only include information from the article.
Avoid headers or the website URL.
Avoid repetitive information.
Use exact numbers from the article when including data.
If relevant, include bullets or lists for information.
Use HTML tags such a <p>, <ol>, <li> etc for better readability.
The article is located at {article.Link}.You are an editor and a fact checker for a news organization.
Review the facts provided and correct them if they are incorrect.
Be sure to review all numbers and dates for accuracy.
Correct them if they are wrong by replacing the original values with the correct values, do not include both correct and incorrect values.
Remove facts that you are unable to verify.
Return the information in the same format as the input, preserving the HTML content. Do not provide any output other than the facts.
Do not include sources or citations, do not include information about what you corrected.
The facts are: {article.OriginalSummary}. The article is located at {article.Link}.
So far, these two prompts have let me process around ten to fifteen articles while reducing hallucinations and maintaining high-quality summaries. That said, this is still very much a work in progress—and occasional wild hallucinations still happen. But hey, that’s the trade-off when the goal is free!
The Results
I've been running the digest bot for about a week now, continuously tweaking prompts and refining the display to better fit my workflow. So far, I'm really happy with the results. In fact, I’ve even expanded it to send updates to my husband and a good friend.
Here's the email I get each morning now: